My master thesis
Scalable solving of boundary element methods utilizing the Green cross approximation method and GPUs
This project is maintained by Bennet Carstensen
Aug 27, 2017
by
Bennet Carstensen
•
First results - Substituting the farfield
After some time now, I have the first results to present. First the bad news: We are (currently) don’t have a faster solver compared to previous methods, which is rather untypical for utilizing GPUs. On the bright side, we can save 20-26% of memory used by a -matrices at the expense of 20-55% of increased computation time in the -matrix vector multiplication, decreasing antiproportional with the problem size. This in term is heavily utilized in, e.g., Krylov subspace methods to solve system of equations like the discretized integrals we consider.
First lets construct -matrix. We construct the matrix based on the unit sphere as an example surface consisting of triangles. will also describe the dimension of the matrix. We set a maximum leaf size of 64 in our cluster and a maximum error of the adaptive cross approximation of . Furthermore, we apply quadrature of the order of 2 to regular integrals, 4 to singular integrals and 8 to approximate Green’s second identity, resulting in the following memory requirements for -matrix of differrent dimensions:
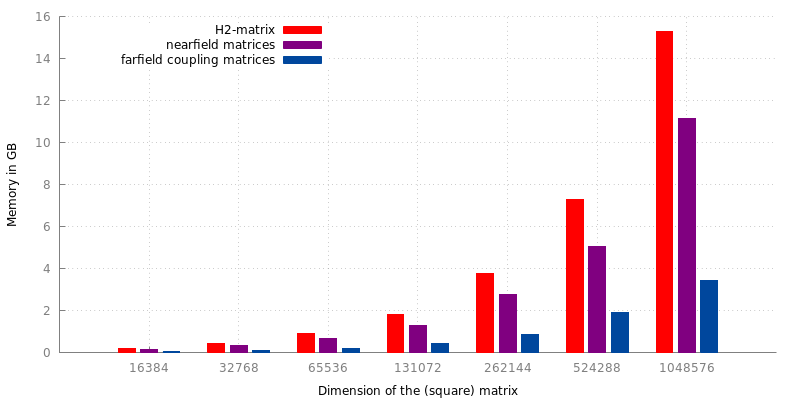
Figure 1: Memory requirements of -matrices and their proportion of neafield and farfield coupling matrices.
For our current algorithm, we concentrate on the farfield part of -matrix which occupies the 20-26% of memory we want save. The details of our algorithm will follow. Regardless, we are basically computing the all farfield coupling matrices on-the-fly during the matrix vector multiplication phase instead of conventionaly saving the matrices and multiplying them with the input vector.
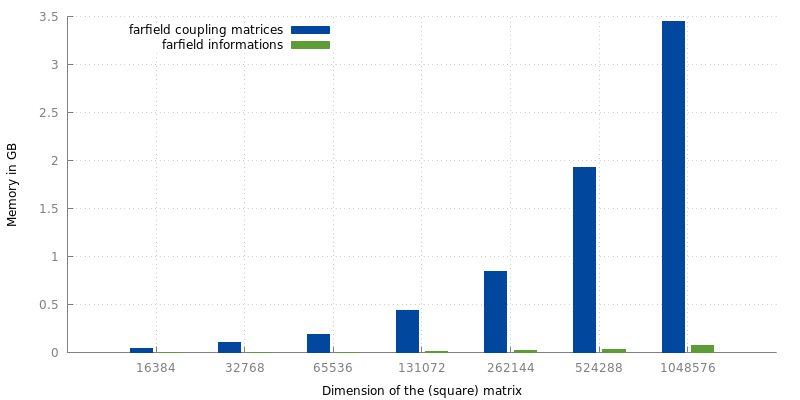
Figure 2: Memory requirements for saving the coupling matrices compared to the informations needed to compute those matrices.
The information needed to compute the coupling matrices and to perform the follwing matrix vector multiplication, including the
- geometry,
- quadrature points and weights and
- bookkeeping informations of the
- dimensions of each farfield matrix and
- their row and column offset relative to the whole -matrix,
occupies only a fraction of the memory used to save the matrices directly.
While this a lot of memory one could potentially save, for 3D problems, the tasks for computing those matrices involves calculating 4D integrals for each entrie of each farfield matrix.
Although this is an utterly computational heavy undertaking, evaluating quadrature rules can be efficiently vectorized thus being well suited for GPUs. We performed the following tests on a Intel Xeon E5-4640 CPU and a NVIDIA Tesla K20X GPU accelerator.
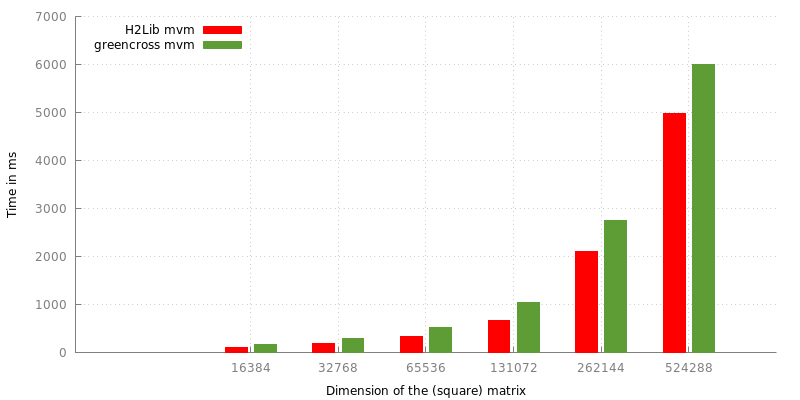
Figure 2: Time needed to perform the standard -matrix vector multiplication compared to the same task while computing the farfield matrices and their part of the product on the GPU.
As already mentioned, computing the coupling matrices on-the-fly, even when done on the GPU, performes slightly worse than solely performing the matrix vector multiplication. Still, saving the relative amount of memory observed here, this algorithm might be a real consideration where memory is sparse compared to computing power. One might also consider distributing the computations accross multiple GPUs thus speeding up the performance.
Furthermore, consulting Figure 1, another 70-75% of the memory required for a -matrix occupies the neafield. Since this represents the singular integrals, additional work needs to be done to compute it on-the-fly and integrate it in the current algorithm while keeping work done by threads and GPUs balanced. The result would be saving almost 90% of the global memory requirements of -matrices.